
In this article, we will give a simple tutorial to build an Apache Mahout’s user-based Collaborative Filtering Recommender System. This article also demonstrates how we transform normal data into Mahout-friendly data (in this case, Ebook’s data).
Apache Mahout
Apache Mahout is an open source machine learning library developed by apache community. Mahout supports a wide range of machine learning application such as clustering, classification, dimension reduction, and collaborative filtering.
Apache Mahout is completely free for use and download. Check it out here.
Why we chose Apache Mahout?
- It is scalable and supports Hadoop
- It implements generic and standard collaborative filtering algorithms ( matrix factorization, matrix multiplication, …)
- Apache Mahout is customizable
Type of collaborative filtering algorithms:
Let’s talk about Collaborative Filtering algorithm. There are two types of collaborative filtering: Neighbor based and Latent Factor based. In this section, we will briefly discuss all of those algorithms
Before going into detail, let’s consider the following problem:
- User U visits a bookstore (for example alezaa.com) and read-review several books (A_i) i=1..n.
- find a list of books (B_j) j=1..m that matches U‘s preference
Neighbor-based algorithms:
Neighbor-based methods can be considered as the earliest approaches for Collaborative filtering. In general, neighbor-based methods can be divided into two subcategories: item-based an user-based.
Item-based algorithm:
This problem can be solved by calculating the similarity between two items. After that, we can predict the preference of U on item b using the calculated similarity values between b and (A_i)
User-based algorithm:
The user-based algorithm does not calculate the similarities between items. In fact, it calculates the similarities between users. In another word, User-based algorithm aims at finding a group of users that have the similar ratings on Bookstore’s books with U. Based on that, we could find (B_j)
Latent factor algorithm:
Unlike Neighbor-based algorithms, Latent factor algorithm tries to learn features from User’s preferences. After creating a sparse user-rating matrix, latent factor algorithm uses Stochastic Gradient Descent or Single Value Decomposition to learn the most suitable features for items and user’s preference.
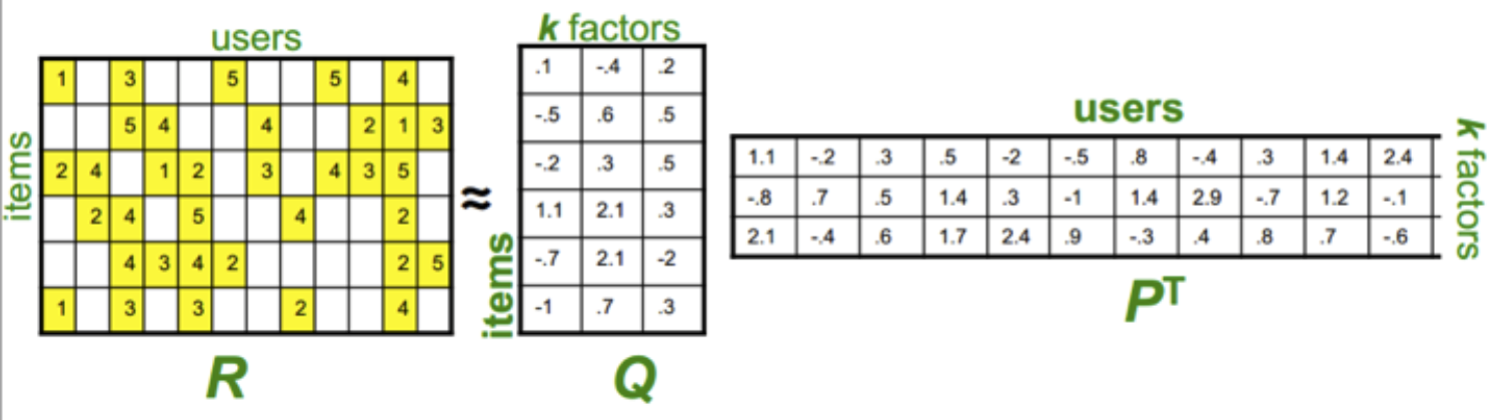
The process mentioned above can be illustrated by the following pictures.
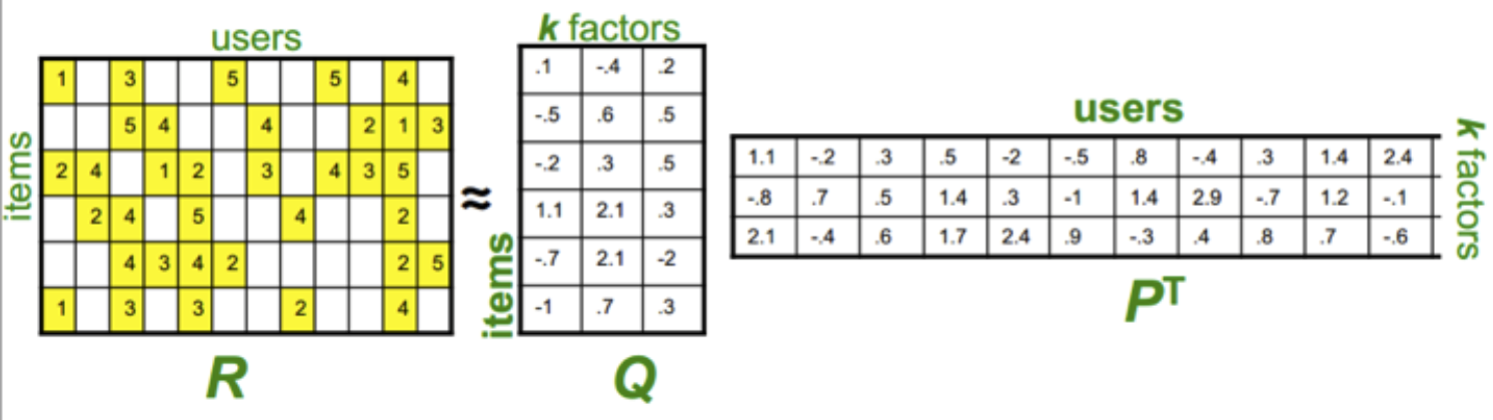
The first matrix is the input that we collected from our data. The second and the third matrices are the decomposed matrices that we computed. k is the number of features that we want our algorithms to learn from the given data.
For each user U and an unrated item i of U, we can estimate the rate of U on i by multiplying the corresponding row and column of the second and the third matrices.
Type of Apache Mahout’s similarity distances
- Euclidean distance: This measures the Euclidean distance between two users or items as dimensions. The preference values will be valued along those dimensions.
- City Block distance: A simple City Block or Manhattan distance between items or users.
- Uncentered Cosine distance: This considers the angle between two preference vector as the distance.
- Tanimoto distance: this is the number of similar items that two users bought. This type of distance does not consider the preference values.
- Loglikelihood distance: A modified version of Tanimoto distance.
- Pearson distance: The Pearson correlation between two items (users). It can be described as the linear correlation, ranging from -1 to 1. Value -1 means total negative correlated, value 0 means there is no correlation, and value 1 means total positive correlated.
- Spearman distance: Similars to Pearson correlation but uses relative ranking preference values instead of the original preference values.
Note: For our book data, if we do not transform the user-collection database, Tanimoto and Loglikelihood distances are the most suitable distances. After transforming data, we can use any of those mentioned distance above. In our real system, we implemented a new similarity distance that takes user’s updated time in consideration.
Transforming book data
We currently use the use-collection database of Alezaa.com and modify it into rating preference data. The rating data is created by the following steps:
Step 1: Read the input data
User-collection database is stored in CSV format with 5 different fields: userID, isbn, order, created time, and updated time. We use 4 out of 5 features except the order feature in order to create the rating data.
Step 2: Convert book data into rating data
Apache Mahout only accepts numeric data, the currently used timestamp data does not hold any significant meaning for Mahout. We need a procedure to convert the timestamp into preference data. Assume that inserting a book into collection increases one’s interest on the book. The same pattern happens for updating collection too.
Taking that into consideration, we can build a simple mahout friendly database using the given user-collection database. For each user u and item i:
- Set the default rating value r = 0
- if u has i in his/her collection, r += 1
- if u updated i in his/her collection, r += 1 (the updated time must be different to the created time)
- if the updated time of i in u‘s collection is still new (less than 5 days), r += 0.5
One can easily modify the algorithms by updating the AlezaaWeightCalculator class in recsys.ml.mahout package.
The output of rating data will be:
The output file is a CSV file which contains 4 fields:
- the first field is the id of a user
- the second field specifies the id of book or article
- the third field shows the rating of selected user for the selected book
- the last field describes the last time the book is modified in the collection (this field will not be used by Mahout)
How to create a simple Apache Mahout’s user-based recommender system
There are 4 steps to build a simple and generic user-based recommender system:
- Load data model. The data model file is the converted rating file described in the last section.
[code lang=”bash”]
DataModel dataModel = new FileDataModel(root.getCurrentMahoutUserBehaviorFile());
[/code]
- Calculate user similarity. Here we use the cosine similarity
[code lang=”bash”]
UserSimilarity similarity = new UncenteredCosineSimilarity(dataModel);
[/code]
- Calculate user neighborhood. K_NEAREST_NEIGHBOR is the number of neighbors taken in consideration
[code lang=”bash”]
UserNeighborhood baseNeighborhood = new NearestNUserNeighborhood(K_NEAREST_NEIGHBOR, similarity, dataModel);
[/code]
- Build Recommender using the loaded data model, user similarity, and user neighborhood
[code lang=”bash”]
UserBasedRecommender basedRecommender = new GenericUserBasedRecommender(dataModel, baseNeighborhood, similarity);
[/code]
- Optional: Build the cached recommender based on the generic recommender
[code lang=”bash”]
Recommender recommender = new CachingRecommender(basedRecommender);
[/code]
To recommend items for a user, given MAX_TOP_RECS are the maximum number of books will be recommended, simply call:
[code lang=”bash”]
recommender.recommend(userID, MAX_TOP_RECS)
[/code]
That’s it …. Simple isn’t it?
Note: You can always customize Apache Mahout by implementing new similarity function.