
Unlike the recent post in our blog which mainly focus on Natural Language Processing (NLP), this article concentrates on a different topic: Outlier Detection. Today, I will give a brief overview about outlier, and the algorithms can be used to find the outliers. The detailed algorithms will be updated later in the following posts in this category.
What and why?
In real world problems, outliers are also called: noises, anomalies, abnormalities, discordances, deviants, …. To begin with, an outlier is defined by Hawkins as: “An outlier is an observation which deviates so much from the other observations as to arouse suspicions that it was generated by a different mechanism”. In other words, an outlier is a data point which has many different properties compared to the natural of the dataset.
Detecting outliers is always a very important task in data mining. Generally, It helps remove noisy data that could affect the final outcome of the mining algorithms. Furthermore, finding outliers could also be useful to find the abnormal characteristics in data generation process.
Some application of outlier detection
Network intrusion detection
The network-based system often store information about operating system calls, network traffics, …. Analyzing these types of data can help us to find the malicious activities that can affect the performance of the whole system.
Credit card fraud
As you may know, using a credit card ( or event internet banking account) we could pay the bill or withdraw money instantly from every place in the world. This is a huge advancement because we do not have to carry a big pile of money with us while travelling. However, due to some accident, users might lose the information of their cards (banking accounts) to some hackers. This leads to some suspicious transactions which are not known to the real owners. This is where the outlier detection techniques come in. They help banks to find the “abnormal” transactions, The bank will then verify the transactions before making it happen.
Medical diagnosis
In the medical point of view, the normal users often have the similar pattern; and diseases often occur with an unusual pattern which reflects the disease conditions. If we could detect the “unusual pattern” we could identify the “potentially” ill patients and do further diagnoses to verify it.
Earth science
Many applications of outlier detections have been implemented in Earth science. For example climates changes, weather patterns, ….
General idea of outlier detection techniques
Detecting outliers can be approached by two different techniques: unsupervised technique and supervised technique. On the one hand, the unsupervised technique is used to find outlier without any prior knowledge about the properties of the outliers. On the other hand, the supervised technique uses a dataset that stores the characteristics of both normal data and outliers then try to find the best way to separate them into two classes.
Unsupervised approaches
There are several unsupervised approaches that ca be used to solve the outlier detection problem. For example:
Statistical model
The statistical approach assumes that data can be modelled in a joint probability distribution. It will then try to fit a certain distribution to the input data. The data that have low fit values can be considered as outliers.
This category has huge advantages on other categories because it can be applied in virtually any type of data. However, optimizing many parameters while fitting data could lead to the overfitting problem.
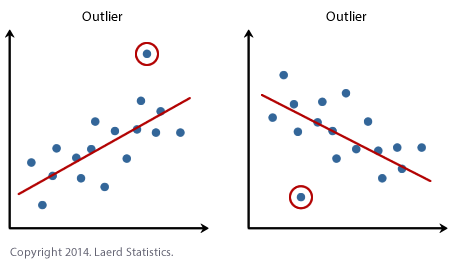
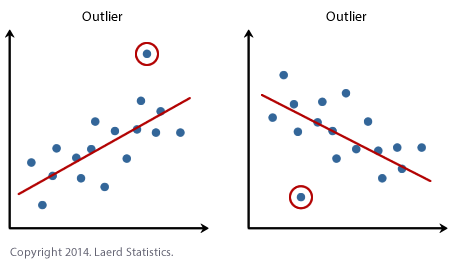
Regression model
Unlike statistical model, regression model aims at finding the trend of data over a specific parameter (such as time). An outlier is detected iff it does not follow the overall trend of the dataset.
This technique has been proved to be very useful for time-series model. We will come back with this model in the next post.
Principal component analysis
Principal component analysis has been widely known for its ability to select important features underlying in the dataset. It is studied that most of the variance of the dataset can be captured at the lower space formed by the top eigenvectors. If the distance from a certain point to the selected top eigenvectors are too much, it could be highlighted as an outlier.
Proximity-based model
In the proximity-based model, a data it considered as a data point in a high-dimensional space. An outlier is a certain point that is isolated from the remaining data. Detecting the isolated data points can be carried out by applying the clustering algorithms, density-based algorithm, or event nearest neighbour approaches
Supervised approaches
Supervised approaches simply consider the input dataset has two different labels: the normal and the abnormal (or the outlier). The outlier detection problem now then become a simple classification problem. We could use any classification algorithm to solve it such as SVM, Neural Network, Linear Classifier, …
However, this is very important to note that: the training data will have imbalanced data (the number of normal data will be much larger than the number of abnormal data). We need to find a way to deal with imbalanced data. One easy solution is sampling ( sampling up the number of abnormal data and sampling down the number of normal data). Another solution could be taken into consideration is applying weights to labels.
That’s it for today. Next time we will talk about Gaussian Regression (an advanced regression technique that uses gaussian distribution and kernel method to predict the trend of data)